


by John Browne, on Aug 30, 2017 5:03:19 PM
We have a new video up today addressing the question of how state is handled in WebMAP apps. This concept is multi-layered and so the video is merely an introduction. More details to follow.
Some of it might be too basic for more experienced web developers, but I wanted to follow the advice of Lewis Carroll's character in Alice in Wonderland:
“Begin at the beginning," the King said, very gravely, "and go on till you come to the end: then stop.”
Those of us who have been punished (or blessed if you will) by remaining in the desktop app development world can find the new world of web development a big lift. Unlike Windows, you now have "front-end" and "back-end" and "full-stack" developers; where in Windows you have a language (like C# or VB.NET) and a runtime (like VB6 or .NET), in web development you have multiple programming languages (like C#, JavaScript, TypeScript), frameworks (jQuery, AngularJS, Knockout, Bootstrap, KendoUI, React), tools (Chrome developer tools, Fiddler, Wireshark), plus miscellaneous bits and pieces (think JSON, AJAX, nuget, NPM, HTML, Razor, Unity, CSS)...the list isn't endless but can appear that way.
It's a lot of stuff to learn.
It's helpful to begin at the beginning: the web was designed to exchange hypertext documents, not build rich applications. If you're interested in learning more about that disconnect, please see the video. Since I don't want this post to resemble War and Peace I'm going to skip over that part.
What is state?
I've heard about state my whole career--people talk about state machines, stateless apps, state this and state that.
So what, exactly, is state?
State is simply all the data and objects an application has in scope at any given point of execution. In effect it's a snapshot of memory. Not all memory. Just the memory as defined above.
As a desktop (ie Windows) programmer, chances are you have never really had to think about state per se. Sure, when you're debugging you want to know the value of locals at a breakpoint. That's state. If you look at the this object and expand it, that's state.
But mostly you don't think about it because Windows takes care of it. When your application runs, Windows allocates memory for it and manages the elasticity of that allocation--expanding it when objects are created and freeing it when objects are no longer reachable. Remember the good old days of malloc() and free()? Yeah, you don't need those anymore. And in Windows these days--using .NET which is, of course, managed code--the odds that another process will rain on your application's parade via a memory violation are pretty low.
If you create an object--like say a user types in an address in an order form--that object will persist until the CLR destroys it because it can no longer be referenced. Keep that object in scope and it will be there long after the Rockies turn to dust (ok, little hyperbole there).
Well, the bad news is the web doesn't work that way. Unlike Windows apps, web apps have to share processes, threads, and resources among all sessions--sessions being short hand for "multi-user"--something desktop Windows doesn't have to deal with.
There are some other key differences:
Object lifecycle
As implied above, the lifecycle of a Windows object is pretty straightforward:
- Object is created (initialized)
- Object is used (data stored)
- Object is destroyed (garbage collected)
- Clean up or finalization code is executed (this.close() for example)
Now consider a web application with multiple concurrent sessions. Lifecycle looks like this:
- Server receives a HTTP request
- Objects is instantiated and initialized
- Object is used by logic code
- Response sent to requesting client
- Object is "suspended" while other threads execute
- Object is cached locally or externally on disk
- Object's memory is released back to the heap
- Original requestor makes new request
- Object recalled from storage (cache or disk), but not reinitialized
- Object is used by logic code, response sent
- Object is suspended; memory freed up
- Rinse and repeat until application closes or object survival time expires.
This last step might need some explanation. Unlike Windows, an app (on a client) running in a browser might just disappear in media res so to speak. The browser might get closed, the network connection might get broken, or the user might go to bed. The server has no idea, since the normal "application termination" event didn't get sent.
Should it hold all the objects forever in some kind of storage, like bodies cryogenically frozen waiting for a cure to the disease that killed them? Maybe if your app will never have more than five users you can get away with that, but what about Amazon.com? Or Expedia? Clearly they have to set an expiration time for objects that are in limbo. And we've all experienced that from a user perspective, where, for example, our banking app tells us for security purposes we've been logged out after no activity for some time. At that point all that state info on the web server is marked for destruction.
At this point any readers still awake might be wondering "Why cache state? Why not just send everything needed with every request?" The short answer is "because performance would be crap." Especially with control-rich forms, multiple concurrent sessions could easily overwhelm a server's ability to respond in a performant manner. So instead you need a way to manage just the changes--the delta--of the state. More on that in part 2 of this blog.
Some other interesting differences:
- View creation/management: All the Windows Forms and WPF classes to create a rich UI don't exist inside your browser of choice, so some combination of stuff that does exist is needed. This need gave us countless JavaScript frameworks and related technologies (like Flash).
- Modal dialogs: in Windows you can put up a dialog and suspend execution until the user makes a choice (think File.SaveAs for example). That dialog can, again, stay up forever if the user gets up from his desk and joins a cult before clicking "Save." That won't work on a web app because you can't force an execution thread to suspend.
- Local access: Windows lets your code access the local file system, devices like cameras, scanners, printers, and card readers, and store persistent configuration info in .ini files or the registry. Except under rare circumstances these are not available to a browser-based app. Among other technical reasons, they violate the "sandbox" concept of apps running in the browser.
- Access to Office: or any apps, for that matter. It's not uncommon to take advantage of the excellent and powerful capabilities of Microsoft Office applications (Word and Excel especially) from your Windows code. Need to run a spell check? Call Word through the exposed API. Need to run a statistical analysis on a data set? Excel has your back. But again, this isn't possible from an app running in the browser's sandbox. You'll have to replace those capabilities in your web app with existing RESTful services or write the code yourself.
So how does it work, exactly?
Let's look at how a WebMAP app handles state on the web. First let's review the architecture:
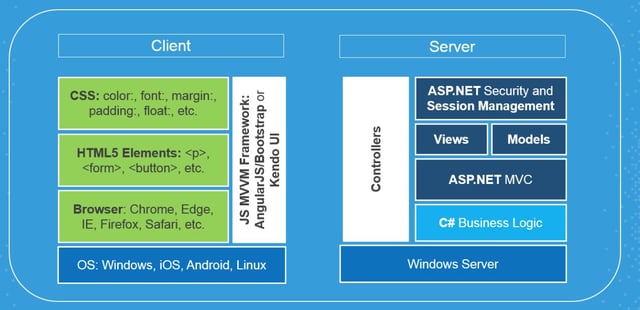
If this looks a little puzzling to you, check out this blog post and this video that drills down on how all the pieces work.
The general event flow works like this:
- Through the magic of KendoUI and JavaScript the initial application form is created in the browser (let's just skip over that for now--or see the links above for more details). The user puts some data in various fields (controls) on the form, then clicks "Submit".
- JS code on the client serializes the data (application state) as a JSON object and sends it as a request via HTTP to the server.
- The server de-serializes the request and routes it to the appropriate logic files, which contain event handlers. They do whatever they need to do (DB CRUD ops, enact business rules, perform calculations, etc).
- The server prepares a new view model of all the changed state--then it serializes this as a response to be sent back via JSON.
- The client receives the JSON message and refreshes the view with the new state information.
- Rinse and repeat.
Let's look at a screenshot of Fiddler running a simple "Hello World" kind of app, migrated from .NET to the web with WebMAP.
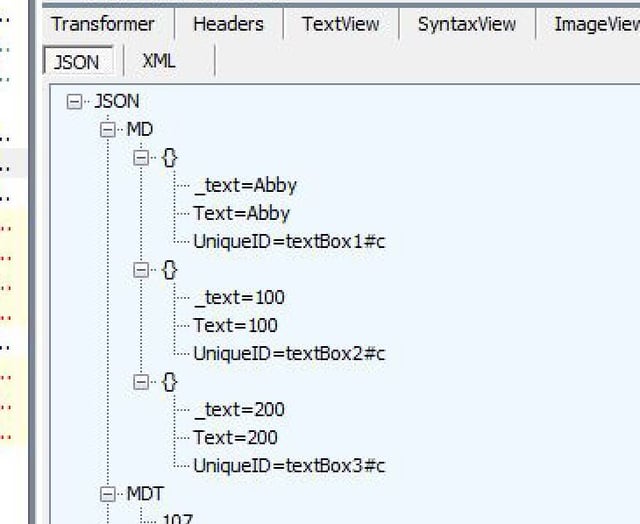
Enlarging the JSON of the response area after a button click event handler we can see the JSON that is returned to the client. Notice the "UniqueID" that is included (in this case the hex value C). Each session gets a UniqueID assigned that is used to clarify every JSON message. The server-side code keeps the state in synch with the client-side code. One thing you can do is set an attribute on an object that tells WebMAP how you want to cache the state of that object.
In the next part of this series, we'll discuss how WebMAP flags state changes to keep the app lightweight and performant, and how it handles refreshing the view after a request. For a more understandable and entertaining explanation of what was covered above, see the video.
