



by John Browne, on Jul 25, 2017 1:43:32 PM
IN THE BEGINNING THERE WAS THE WEB.
Actually in the beginning was DOS, then Windows, then Visual Basic, then .NET. But we'll get back to them later.
Consider: The Advanced Research Projects Agency (ARPA) created ARPANET to ensure digital communications could survive a nuclear attack. Grim. But the idea was pretty cool, which was that you could throw packets of data onto a network and routers would keep passing them along until they reached their destination. If one router couldn't, another could. "Self healing."
ARPANET begat the internet as universities, laboratories, and eventually all sorts of riff raff were allowed to connect until today billions of people are connected via the most complex thing ever created.

Building on the work of Vannevar Bush and Ted Nelson, Tim Berners-Lee took the next internet step when he created the concept of a world wide web and HTTP (hypertext transfer protocol) to connect documents and server pages. "Transfer protocol" is just a fancy way of saying here's how computers can speak a common language. Berners-Lee (considered the father of the web) also created the first HTML specification and the first browser that could render the language. HTML: "hypertext markup language."
Let's doubleclick that a little. "Mark up" is a way of putting metadata on text to describe the structure of a document (using tags like H1, H2, H3), elements like ordered or unordered lists, basic content blocks like paragraphs, even non-textual elements like images. Markup pre-dated the web; SGML (standardized generic markup language) was used by defense and aerospace manufacturers to create technical documentation, for example. HTML included--in addition to the markup tags, a way to include references to pages that resided on web servers--what we call links today--basically an address of a page on a server somewhere.

If you use the wayback machine to look at very early web pages you'll agree that universally they are ugly. Maybe that was ok for displaying research papers or simple tables but as the commercial appeal of the web caught on, people hungered for richer, more exciting web pages. Soon HTML wasn't just a way to mark up text: it was a way to build colorful, dynamic, well-designed user experiences.
And that changed everything.
Let's turn our attention to the server side of all this. You can create web pages using HTML, and store them somewhere, but how to get them? Thus was invented the web server. Let's consider Microsoft Internet Information Server (IIS). IIS is basically a server that listens on a public port for incoming requests for web pages. When it gets one, it notes where it came from (IP address) and retrieves the page (if it can find it), and sends it back to the requester. If it can't find it, it sends a code. (The client has a browser, which is just an app to render HTML in a human-readable format.)
For static web pages that is sufficient. But people wanted dynamic web pages--pages that could, for example, do a database query based on information sent along with the HTTP request. ("Dynamic" also referred to web pages with dancing frogs--something a variety of technologies--some good, some dreadful--took care of on the client side. We'll skip over those for now.) That desire--in effect to make web pages into a kind of software application, even a simple one, required a new set of back end technologies. Staying with Microsoft, they gave us ASP (active server pages) which begat ASP.NET which begat ASP.NET MVC.
IIS was pretty simple: it queued up incoming requests and responded in order. If the network croaked while you were waiting on a web page the browser would time out or hang. No harm no foul--just ask for the web page later when things are working. But for web applications this just doesn't cut it. Say you want to buy a book from Amazon.com back in the day. You put in your payment information and click "submit" and the web site hangs. Now you don't know if your order went through: should you do it again? Will that result in two books where you only wanted one? If you don't do it again will you get even one book? Who knows?
ASP and ASP.NET were, among other things, designed to allow software developers to bring more of the world of desktop software applications to the browser experience. ASP allowed the browser to send some user-entered information, then run server side code to process that information and send a result back to the user. Dynamic page creation. But that raised the ante on managing the back end of the web experience. For one thing, suddenly you had state to keep track of.
It's hard to over-emphasize just how more difficult the life of a web application server is compared to a desktop application. To understand how state makes things much more complex, let's take a ridiculously simple example. Imagine an application that adds two numbers, then tells you the result:
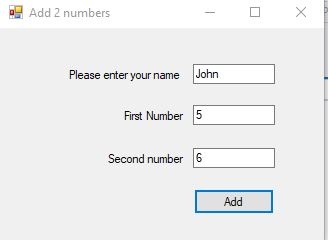
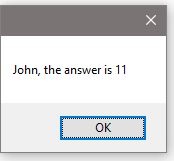
Here we have this tiny app running on Windows, where it has its own dedicated process and related resources. When we run it, we put three variables in memory (name, num1, and num2) and they will stay there until the cows come home or we kill the process, whichever comes first.
It is a stateful application.
Now imagine the same app running on a web server. At first blush it doesn't seem like much has to change, but that's simply not true. For one thing, unlike in our Windows example, this app can have multiple simultaneous users (sessions).
Imagine three users running the app at the same time: Abby, Barbara, and Charlie. The server has to initialize a separate session for each user, and store their local variables in order to run the business logic (adding the two numbers and returning a result). (Ok, I get that in the real world we'd do something this trivial with some JavaScript on the client, but stay with me.)
From the client side, the three simultaneous sessions look like this:

The users each see the form on their browser, the data they entered, and eventually the answer. The server sees a stream of JSON data. {"MDT":[107,107,107],"NV":"000","MD":[{"Text":"Abby","_text":"Abby","UniqueID":"textBox1#c"},{"Text":"100","_text":"100","UniqueID":"textBox2#c"},{"Text":"200","_text":"200","UniqueID":"textBox3#c"} which sort of translates into [object/data/session] [object/data/session] [object/data/session] and so on.
Each user (Abby, Barbara, and Charlie) initiates a session that gets sent to the server; each has a response that involves a new view on the client. Those sessions can persist on the client: Barbara could change one number and click "Add" again. From the server's perspective, is there any persistence? In the case of Barbara, will the client send all the state back to the server or only the changed data?
First Barbara does this:
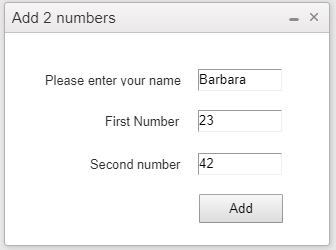
Then she changes one number:
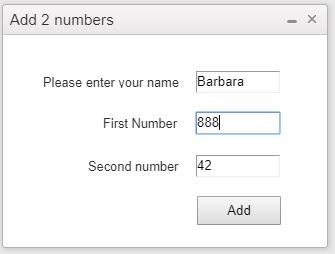
If the app were running (still) in Windows, only the value of textBox2 (with the label "First Number") would be changed, because the state is persistent until the app terminates or the program explicitly destroys the objects in memory. But this is a web app and the server doesn't work like Windows.
Obviously the simple answer is that we send all the state (the values of all three fields, along with their session ID and object names) to the server and it sends back the answer.
With a trivial application like this that would be fine. But no one would actually build such an app. Instead, real-world applications typically have far more complex state--imagine dozens or hundreds of data-bound controls in the client view, with the back end processes focused on database CRUD operations combined with business rules. These apps are dense. The amount of state for a single view can exceed 1MB. This quickly becomes unmanageable since network bandwidth is not unlimited and neither is server RAM.
Here's how WebMAP address this, which is ubiquitous among the migration projects our customers deal with. State persists on the server side as an in-process object associated with a discrete session. As the user changes some data in the client, that data is marked as "dirty" and that revised data is serialized for submission to the server. The controller on the server, having de-serialized that revised state, responds according to the model (ie business logic) and sends back a new view, again just with the delta from the current view. The client-side framework accepts the serialized state delta and builds a new view for the user. State on the server can "time out" and either be destroyed entirely or serialized to a more persistent storage like disk. This depends on what the business requirements of the app are. In some cases you don't want a user to walk away from an incomplete session and return at any time in the future; at other times that's exactly what you want. Specific examples of both cases will be left as an exercise for the reader.
This overview describes a straightforward migration architecture from Windows desktop to HTML/ASP.NET MVC. There are many cases where business rules can move from the backend to a JavaScript-based algorithm inside the client, avoiding server round trips. In our practice it's common for customers to be in a muck sweat to get their Windows app running as a proper web application and this architecture is perfect for a fast migration and deployment. Once the app is running on the new platform, profiling and monitoring tools can provide data for where performance improvements can be found.
