



by Mauricio Rojas, on Oct 4, 2022 7:28:00 AM
Have you heard the news?
There is a great new platform for Data Science and it is called Snowpark.
But like many others, you might feel a little lost about it.
Don't worry that is very common.

Snowpark can seem complicated, but it is in fact very simple. First, some background.
Why do we need Snowpark?
- over-complicated architectures
- increased maintenance
- additional operating costs due to:
- broken pipelines
- slow transformations
- difficulty to trace or debug
- feature engineering
- transformations
- ML scoring
- a wide array of business logic
I can already do a lot of stuff already in SQL. Do I need another language?
Yes. Of course, you can do a lot already with Snowflake SQL.
For example, let's look at this:

As seen in the above code snippet, you can perform compute-intensive features in Snowflake SQL such as:
- Calculate number of sales per product for last week/month/year
- Rank products within different product categories by price, revenue
- Calculate share of revenue or margin for a product
- Find the lowest ever sales price for all products in each product category.
But there might be some advantages to looking at other approaches.
SQL versus DataFrame API
Let's compare using SQL versus using a DataFrame API. Some things will be similar, but in some areas there can be advantages.
Write and use functions
These two tasks can be done both in SQL as in Snowpark.
| SQL | SNOWPARK |
 |
 |
But Snowpark can be used to bring custom business logic written in other technologies like Java or Python. For example, you can look at this example by Felipe Hoffa to create a language detector UDF:
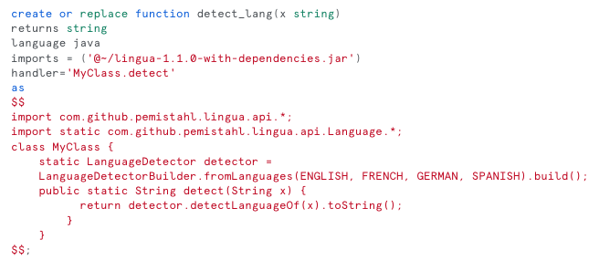
Or you can use more complex functionality like Facebook Prophet or other ML trained models.
But as you can see, Snowpark can be leveraged to keep most of your pipelines in pure SQL and utilize Snowpark's capabilities to wrap additional functionality. Or you can start using more extensibility in other parts of your data pipelines.
Code Writing
SQL is an amazingly powerful tool. You can orchestrate your code from Snowpark and use SQL for some operations, but you can also take advantage for the DataFrame APIs. Using DataFrame APIs can bring some benefits as shown below.
SQL code writing can be monolithic or harder to debug
This is specially true for complex views with with many subqueries. If you have a subquery it might be sometimes difficult to run it in isolation.

With the Snowpark DataFrame API, some of the pipeline operations are easier to separate, debug, and track.
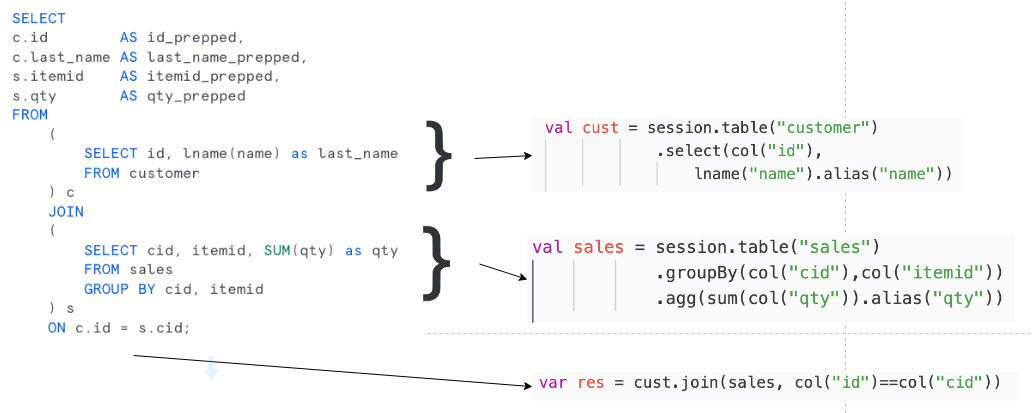
Repetitive Tasks
SQL does not provide a lot of mechanisms for repetitive, tedious operations. But in Snowpark these tasks can be capture into reusable blocks:
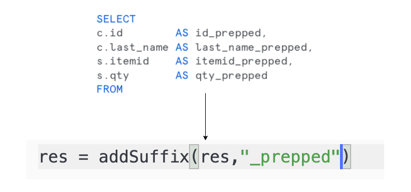
And that doesn't mean you need to just use the DataFrame API if you have pipelines (for example, Hive pipelines) where your pipeline is mostly reading SQL and using it to drive the execution. You can consider doing the same in Snowpark, but now you can now take advantage of this API and provide hybrid approaches where your SQL teams can use a lot more functionality where they are more comfortable.
How does Snowpark work? Do I need Spark to run Snowpark? How does it compare to Spark? Where is it executing?
So first, Snowpark and Spark are different, but they are similar in their purpose.
Spark is a distributed compute platform. In spark you usually have a driver program that will connect to the cluster and push down the work.
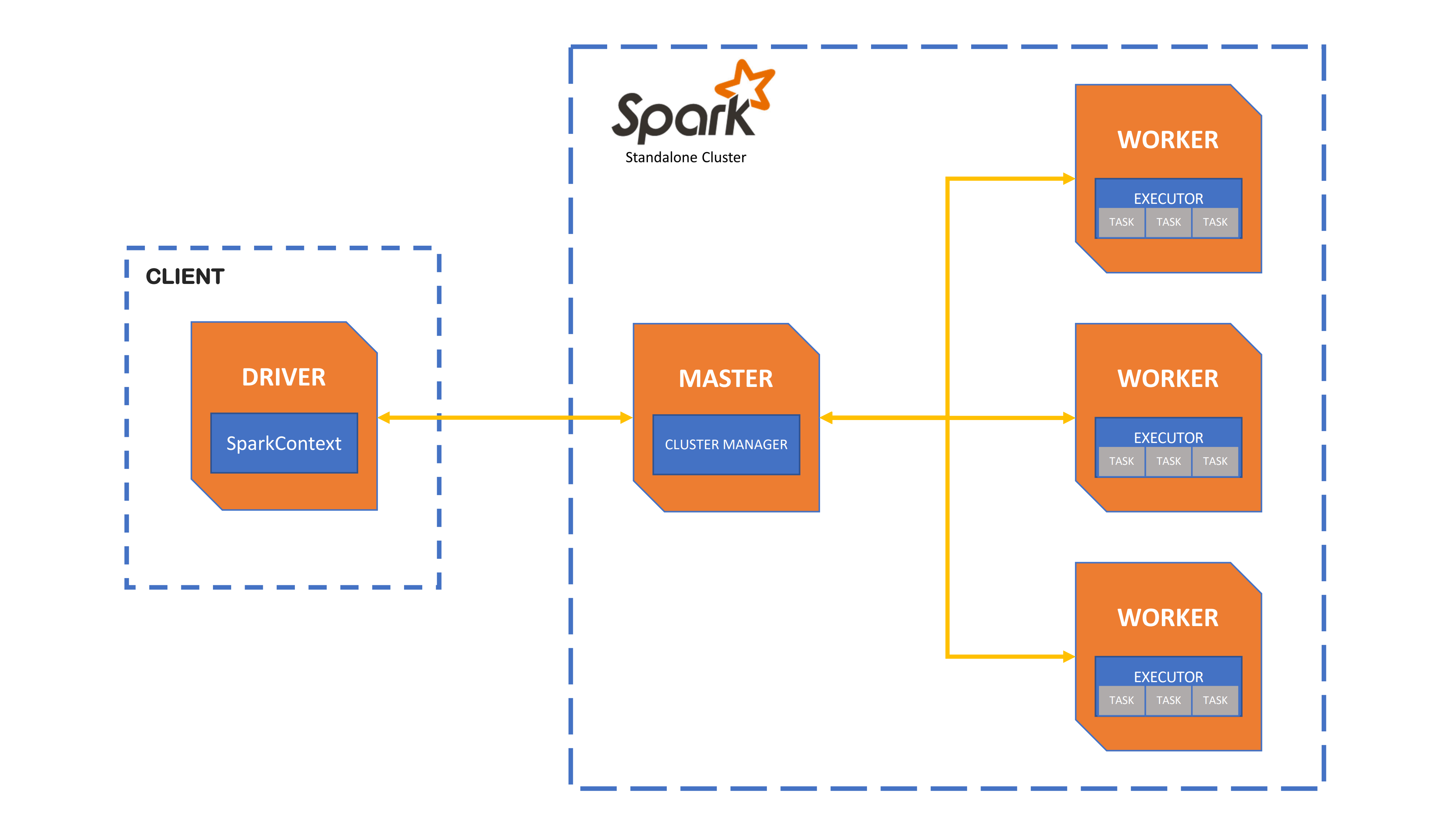
This cluster can be small or big, and usually you have a team that need to setup and configure this cluster. Some vendors allow for some level of cloud provisioning, but there is still some knowledge needed to setup this cluster.
Snowpark does not need Spark to run. Snowpark leverages the computational power of Snowflake's warehouses making provisioning and scalability easy to operate.
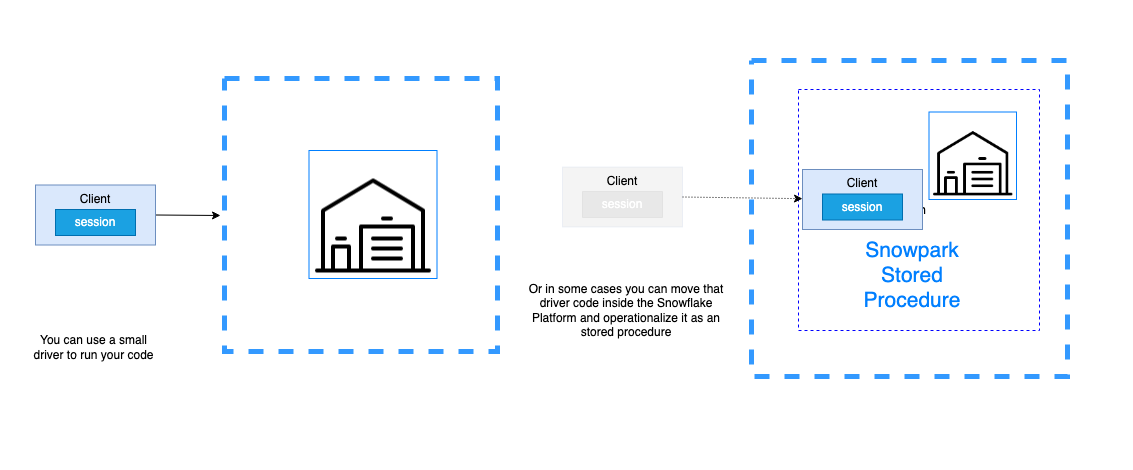
You do not need Spark to run Snowpark, but you can run Snowpark code from Spark. Unlike Spark jobs, the Snowpark code does not need to take advantage of the Spark cluster capabilities.
You can run code using your spark master node to act as the driver to run Snowpark code from within your cluster. In those scenarios, the Snowpark code does not require a big master node as those operations will be happening in the Snowflake warehouse.
In Spark, you typically will use a DataFrame API. The chain of operations that you apply on your DataFrame will be translated into a Spark Query Plan that will be executed in the Spark Cluster.
Snowpark is similar, but your DataFrame operations will be translated into a Snowflake Query Execution Plan that will be passed down to the Snowflake warehouse, as you can see in the diagram below.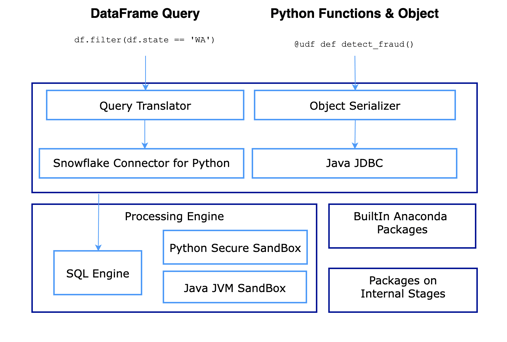
Snowpark code is executed inside the warehouse. One of its benefits with respect to spark is that data does not need to be moved from the warehouse to the computational unit. Everything will happen inside the warehouse.
In Spark, there is a lot of data movement between the Spark cluster and the warehouse:

A lot of this data movement can be reduced or eliminated with Snowpark providing big savings in compute and transfer, and helping to use data governance.
I want to know more. Where can I find additional resources?
Snowpark is growing everyday, but there is already a lot of material that you can use to get started. As mentioned previously, you can take advantage of Snowpark in your language of choice. Please check the documentation for Snowpark for each platform:
There are also many good links that will help you get started. For now, here are just a few:
- Getting Started QuickStart
- Advanced ML workflow QuickStart
- Snowpark for Python Examples Repository
- Using Snowpark with Airflow
- Data Masking or Anonymization in Snowpark
At Mobilize.Net, we clearly see the potential in Snowpark. If you have any questions or you need help moving from Spark to Snowflake, just contact us.
